This is the first in a series of posts where I take a look at notoriously one-sided baseball trades, using the baseball trade networks published on this site earlier in 2022. I won’t necessarily rank these deals in any sort of order; rather I will pick out a few from the network trade graphs and provide some analysis and context for some of the most notorious transactions.
If you haven’t seen the trade networks previously, here’s a link.
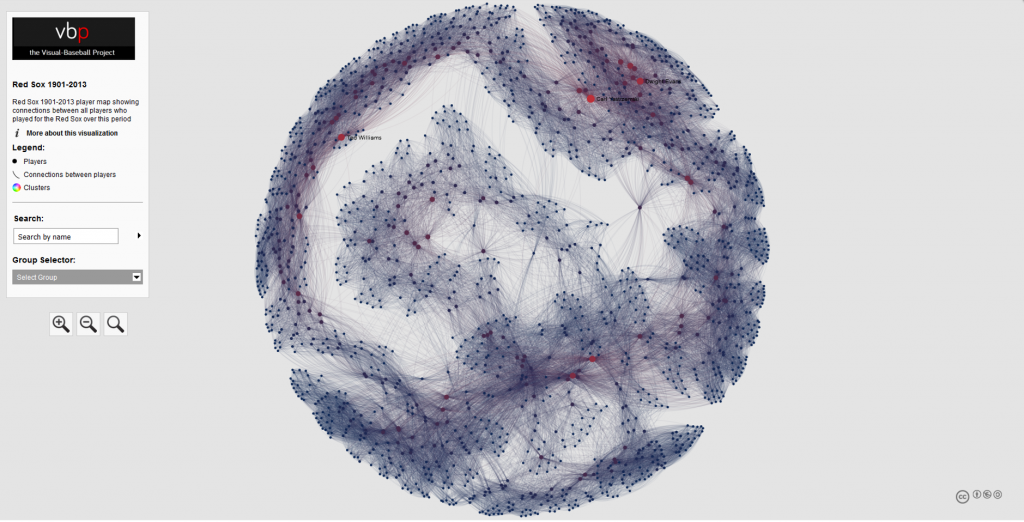
The networks were built using data from Retrosheet and Neil Paine, loaded into Gephi, a network analysis and visualization tool, and ultimately pushed to the web where I could finish styling the graphs. Graph nodes (the circles in the networks) are sized based on the total future WAR (Wins Above Replacement) accrued by the teams involved in the trade. All values must occur at the major league level (MLB), so players involved in the deal who don’t reach the MLB level with their new team will have a zero value. Only the cumulative WAR value while playing for the new team is included; we are not calculating WAR once a player leaves one of the teams involved in the transaction.
Finding a bad trade by scanning the networks is more an art than a science; the key is to look for large nodes (indicating a lot of future WAR value), and then dissecting the trade to see how much value each team received. The other alternative is if we already know the player(s) we are looking for; in these cases we can perform a simple search to find the trade. Here’s a classic example that Red Sox fans would love to forget – trading future Hall of Famer Jeff Bagwell for journeyman reliever Larry Anderson. Let’s go to the Red Sox trade network and search for Jeff Bagwell.
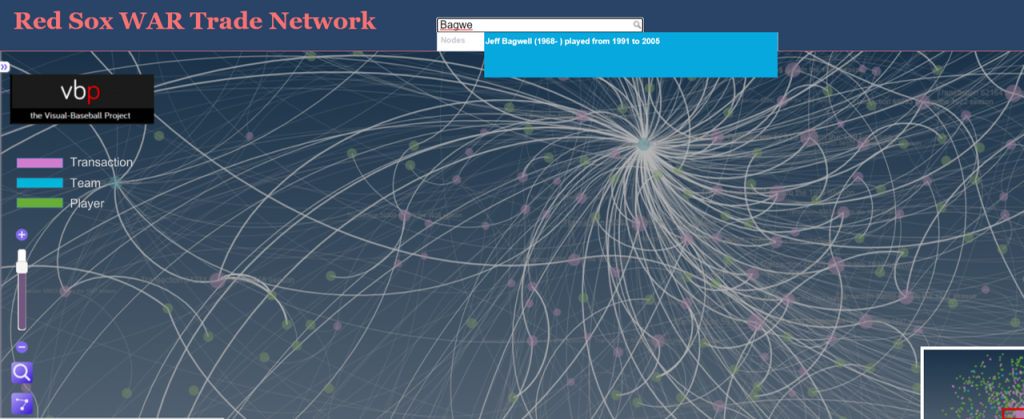
Typing in Jeff Bagwell locates him quickly within the trade network. Note that even if a player is involved in multiple trades to or from the same team (rare but possible) the search will locate each transaction. Here’s the Bagwell transaction, showing his player node and future WAR value connected to the transaction node; every player involved in that transaction will be connected to the trade node, as long as there is some future WAR value. If a player in the trade did not play in the majors for the receiving team, they will not be reflected in the graph. Here’s a view of Jeff Bagwell relative to the trade:
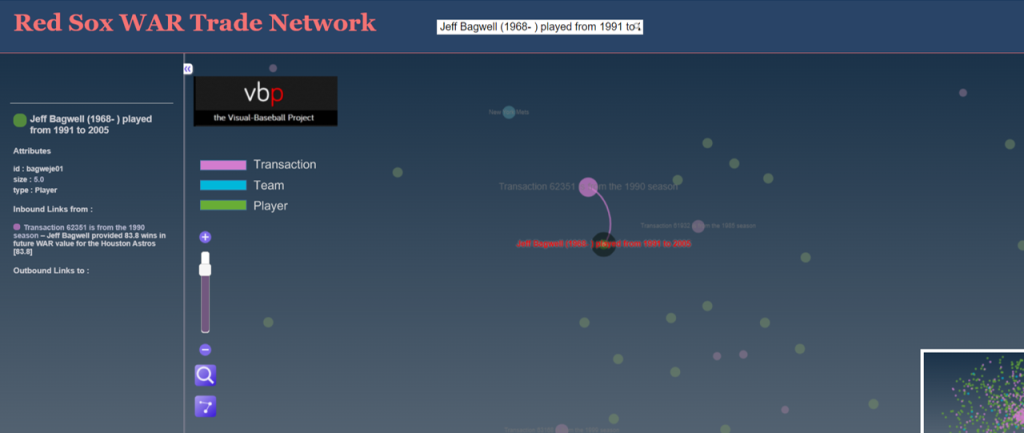
We can also click on the transaction node to see the value provided to each team by all of the players involved in the trade, again assuming they spent time with the team and were not limited to the minor leagues. Clicking on that node will display the respective WAR values in the sidebar on the left of the screen:
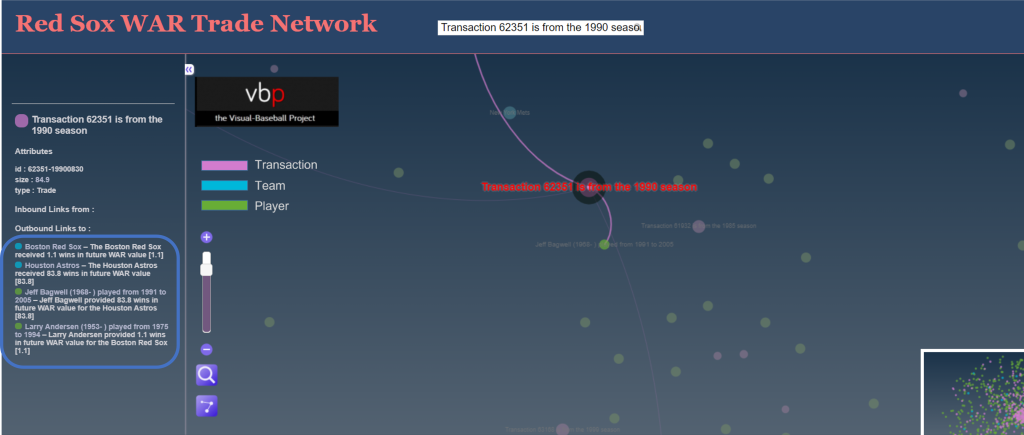
Here’s where we get to the details of the trade, and specifically the direct benefits accrued to each team. The Red Sox received 1.1 future WAR from Larry Anderson; to put this in perspective, we might expect this sort of value for an average player for a single season. The Astros, on the other hand received an incredible 93.8 WAR from Jeff Bagwell, or close to 6 WAR per season for 16 years! That is a Hall of Fame level performance, and it eventually led to his selection to Cooperstown in 2017. Here’s a profile that mentions the one-sided trade.
While we have the Red Sox network open, let’s see if there are any other disastrous transactions (other than the cash sale of Babe Ruth to the Yankees, technically not a trade). After scanning the network, we find this one from 1928:
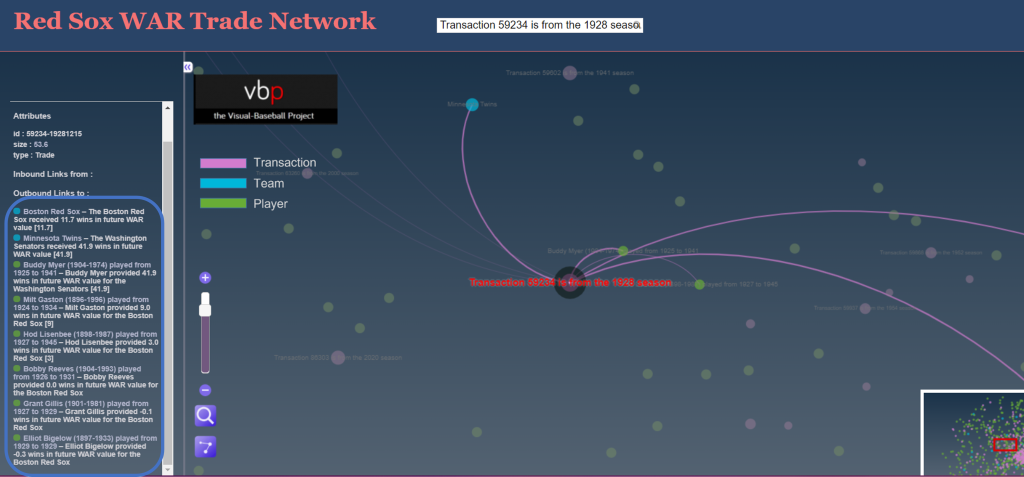
This one is clearly not a Bagwell-level disaster, but was still quite negative for the Red Sox, with a WAR differential of 30 points. The primary villain here is Buddy Myer, a solid infielder who hit .300 or better seven times for the Senators. Not a major star, but the owner of a very nice career, including leading the American League in batting average in 1935.
Let’s try to find one more before closing this piece, this time favoring the Red Sox. We zero in on this deal:
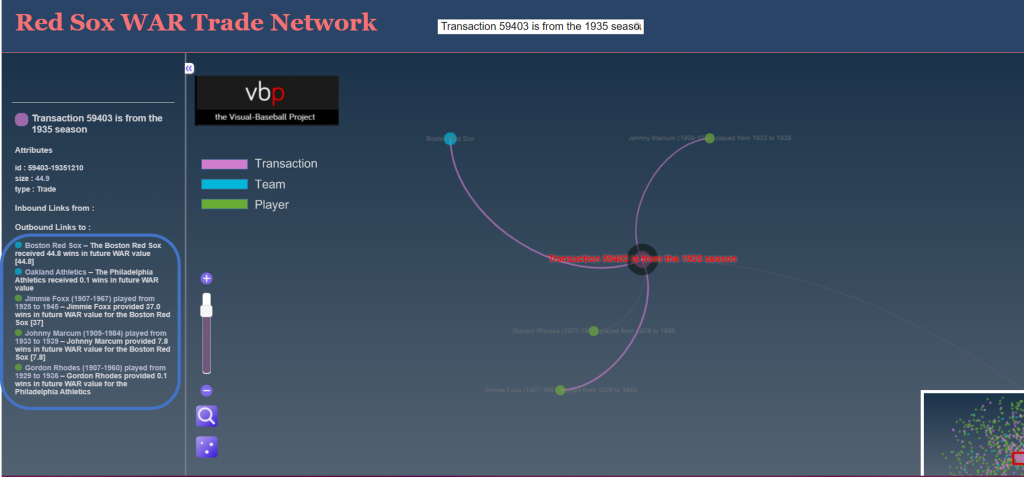
The Red Sox netted nearly 45 future WAR value while surrendering just 0.1; most of the benefit was generated by slugging future Hall of Famer Jimmie Foxx, but they also received a nice three season contribution from pitcher Johnny Marcum. Note how we also removed nodes not involved in the trade by clicking on the edges icon on the bottom left of the display area; this makes it easier to focus on the details.
Feel free to try your hand at finding more of these one-sided deals in the Red Sox or any other trade networks. I’ll be back with some other teams before long. Thanks for reading!