Happy day! Just finished uploading the 2021 baseball dataset from the Lahman baseball archive and Baseball-Databank, just in time for the 2022 season. Next step is inserting and updating the existing tables (with data back to 1901!) with the 2021 season stats. I can then move on to the fun side of the equation – updating existing visualizations and creating some new analyses and visuals. Stay tuned!
Category: Data
Batting Explorer 2018 Data Updated
I’m happy to announce that the 2010-2019 version of the Batting Explorer has been updated with 2018 stats, courtesy of the kind folks at seanlahman.com and baseball-databank.
The Batting Explorers were built using the Exhibit software from the MIT Simile project. A wide array of facets (filters) enable searching, sorting, and data discovery in a fun manner, with every batter having his basic stats packaged in a representation of a baseball card. Here’s a screenshot of some 2018 cards:

For the full roster of Batting Explorers dating back more than 100 years, click here. Enjoy!
2017 Baseball Data Updates Coming Soon!
Happy to report that the annual 2017 baseball data has been downloaded from seanlahman.com, meaning it’s time to start the annual updates. This data is a great resource for building many of my data visualizations that are featured in the portfolio section of this site. Likewise, the Retrosheet game event data has also been downloaded, meaning the onus is now on me to run the various upload and update processes for my databases.
Looking forward to putting these resources to work as I make updates to the following data visualizations (among others):
Stay tuned for updates on these and other projects, and please pay a visit to my JazzGraphs site, where the focus is on network graph analysis of jazz artists, labels, releases, and songs. Thanks for reading!
Recapping 2017
Observers of this blog will note that posts were scarce in 2017 – in fact this is the only one, and it’s being completed in 2018! This is the result of a variety of causes, including external projects, busy schedules, and focus that was shifted in other, unrelated directions. Still, 2017 was not without its moments.
For starters, I managed to create three data visualization courses for Packt:
Retrosheet data for the 2016 and 2017 seasons has also been downloaded, and is in the update process as we speak, which will enable some new visualization work (and perhaps a new book title) in 2018. Soon, annual season data from the Baseball-Databank and Sean Lahman will be available as well.
I’m also in the process of launching a new site at jazzgraphs.com, where I’ll use network visualizations to uncover the complex web of relationships between jazz musicians, labels, and recordings. Posters and a book are in the plans for 2018, so stay tuned.
Wishing all a happy and prosperous 2018, and I promise more content to come this year!
Exploratory DataViz Part 2
Having discussed some of Exploratory’s cool features in a prior post, I thought it would be fun to continue the exploration using JSON data as a starting point. I happen to have a fair amount of JSON on hand, thanks to a series of network graphs produced using Gephi and sigma.js, so why not put it to use with Exploratory and start creating a new dataviz?
If you have previously worked with JSON, you’re no doubt aware that it can be a bit fickle – miss a bracket or brace in one place and the entire file fails to load a visualization. However, knowing that my JSON has been successful in producing network graphs (see here for examples), I figured it was worth a shot with Exploratory.
To begin, start with the local import option, selecting the json option, and pointing it to your local file. Give it a name, run the process and cross your fingers! After a few seconds, I’ve got my results, and Exploratory has done a good job categorizing the data:
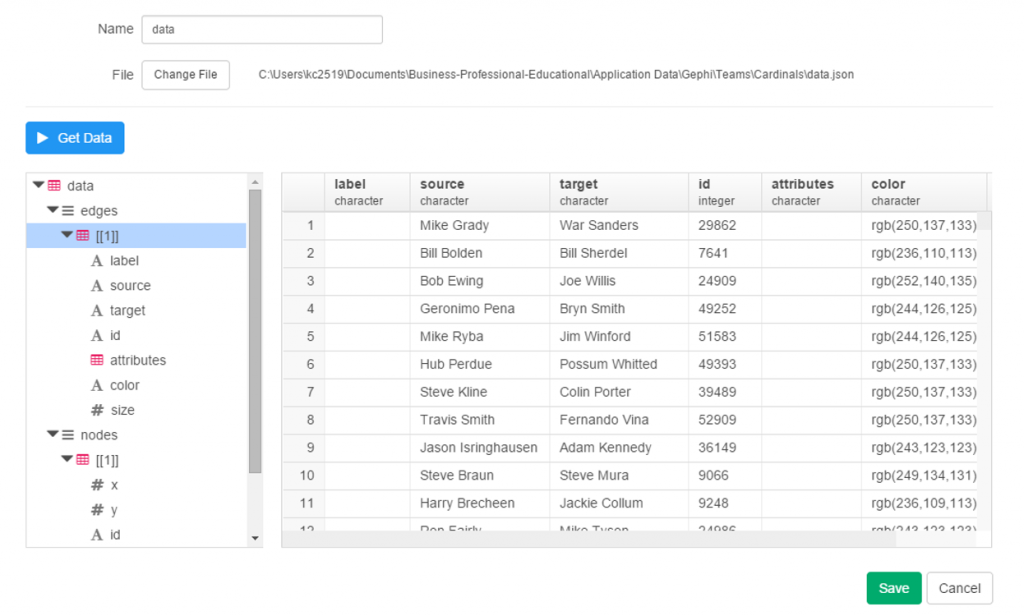
Since this is network data, we have nodes and edges, as well as any additional attributes, such as color or size. Exploratory has picked up those groupings, first the edges, and now the nodes.
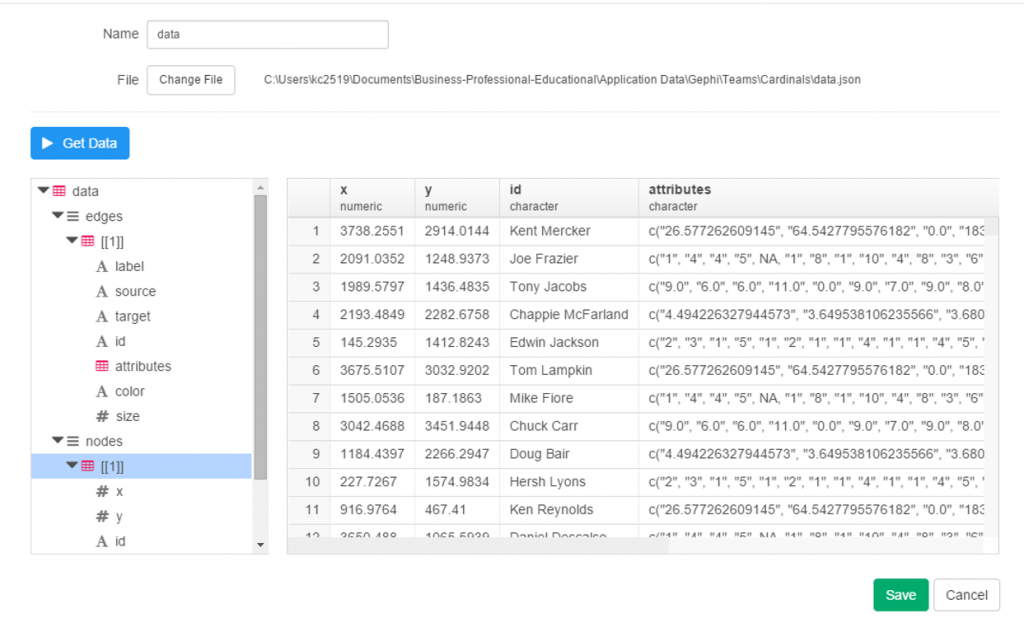
Finally, the attribute values:
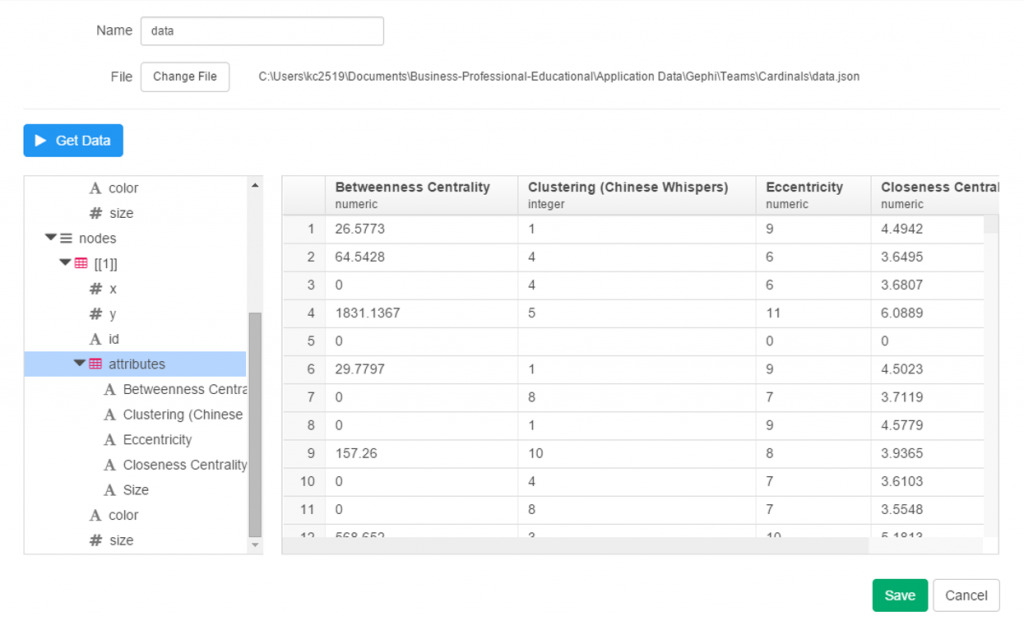
Since we’re satisfied with the import, we can move on to the summary data, which in this case doesn’t make a whole lot of sense. No matter, let’s see what can be done with some charts and analysis.
To start with, we have x and y values associated with each node, which sounds like a perfect candidate for a scatter plot. We add the x value to the x-axis (how convenient was that!), the y value to the y-axis, node size as the Size attribute, and finally the Eccentricity attribute for color. FWIW, eccentricity is not a measure of flakiness, but rather the distance between the most remote points in a graph. This is where the six degrees of separation (or Kevin Bacon, take your pick) concept comes into play; an eccentricity value of 6 equates to 6 degrees of distance. Here’s our result:

Not bad, eh? We can also hover over each node to see who it is (after adding Id to the Label field):
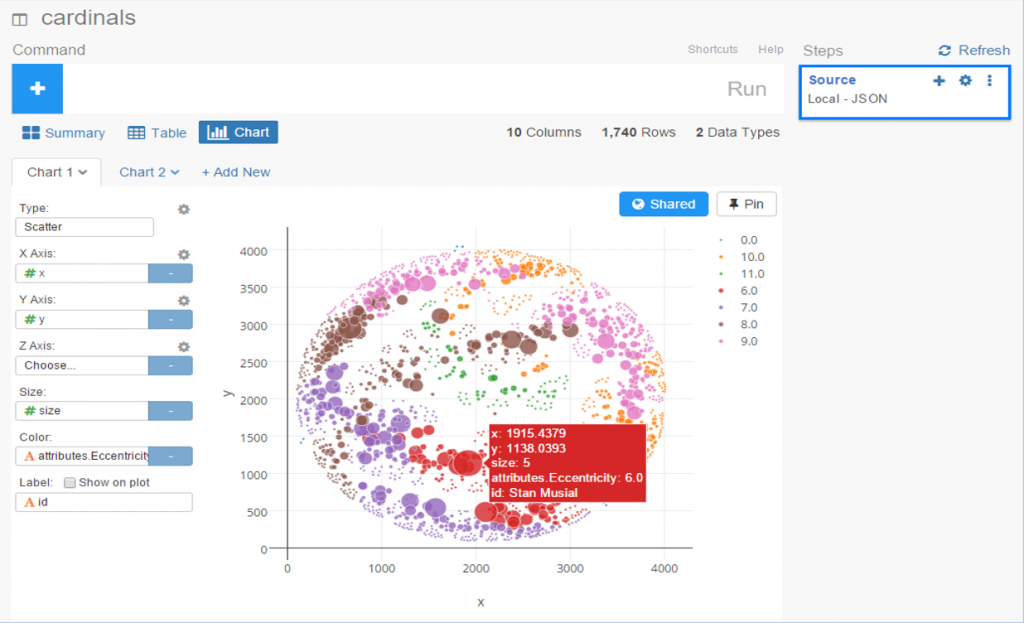
We still have a lot of activity in a limited space, so now let’s use a simple filter (see the command line at top) to grab the top 50 values, and see the results:
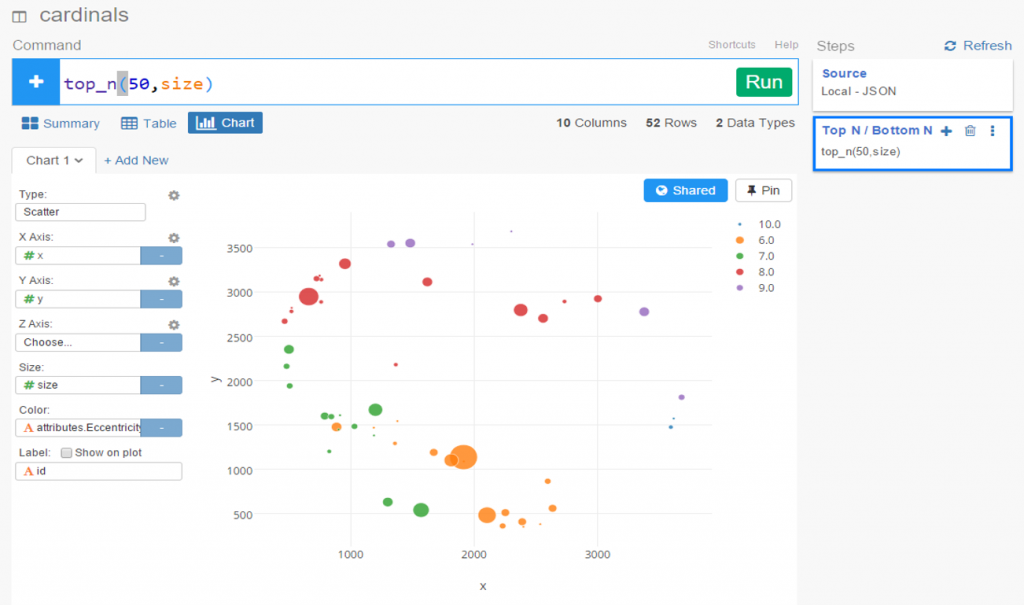
Now let’s create a new branch to explore further. I would like to sort my dataset using the Betweenness Centrality attribute, but there’s one problem – it’s a character value at the moment, so it doesn’t sort numerically. No matter, we can fix that easily using the Mutate command to convert the variable type. This can be seen in the right margin, where Exploratory conveniently stores all actions. Now we can sort our values in descending order to understand who is most influential in the network (at least by this measure). FYI – Betweenness Centrality tells us which nodes others must pass through most frequently to connect elsewhere within the network. Typically, but not always, it is someone centrally located within a network; sometimes it may be a less influential character (Pedro Borbon in this case) who connects more distant groups to one another.

So there you have it, another quick walk-through with Exploratory. Before I sign off, here’s the live scatter plot you can play with via the Exploratory server. Be sure to use the simple zoom features to traverse the chart!
[iframe src=”https://exploratory.io/chart/kc2519/1e4b6b0c24e1?cb=1467821749896&embed=true” width=”100%” height=”600″ frameborder=”0″]
Open Source Data Viz: Exploratory
It’s absolutely a great time to be alive and involved in data viz, courtesy of the wealth of exceptional open source projects. Several recent open source discoveries are currently on my radar, and worthy of further exploration. Over the next few weeks I’ll examine a few of these options, using baseball data (of course) to illustrate the possibilities within each application. Specifically, we’ll take a look at Trelliscope, bokeh, rbokeh, and Exploratory, and provide some insight and examples into how each of these projects function. This post will focus on Exploratory, an exciting new tool from Kan Nishida.
Exploratory is another R-based application that leverages a multitude of R capabilities while providing its own intuitive interface. While still in beta testing, Exploratory appears to have a very bright future as a powerful visualization tool that allows non-coders to tap into the enormous power of R. The ability to harness a considerable portion of the R language through Exploratory’s GUI is a powerful option for those (like me) with limited R experience and expertise.
Exploratory has a very clean, intuitive interface that may feel a little unusual to long-time R users accustomed to multiple panes and workspaces. Yet beneath the surface, it possesses considerable power, as we’ll see in this tutorial. To start our process, we’ll need a data frame, a familiar object for R users. Let’s begin by examining our data frame options.
First up, we can load a local source file in a variety of formats:
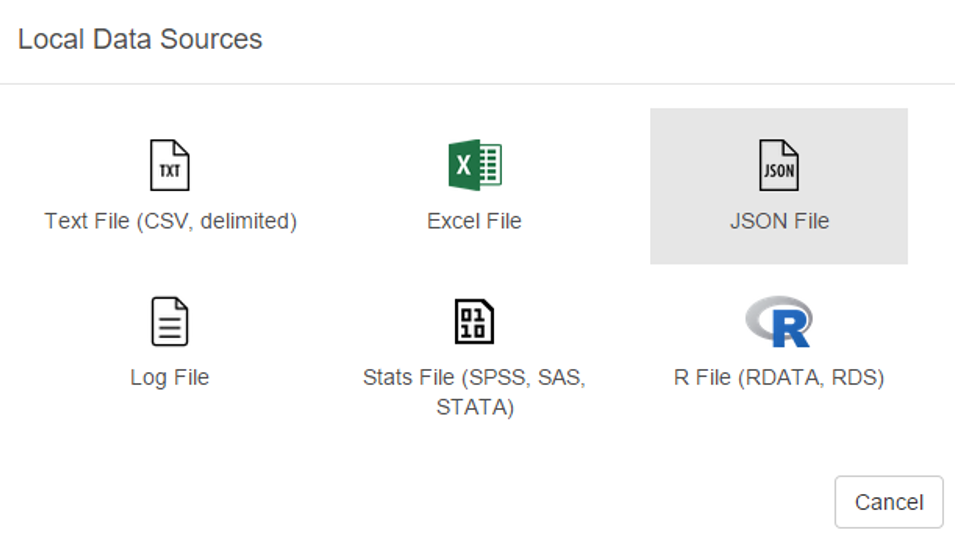
Some of the usual suspects are here – text and Excel files, but we also have the ability to load json data as well as some of the more prominent statistical formats including SAS and SPSS data. Very cool. We’ll come back to this later.
Now let’s see the remote options:
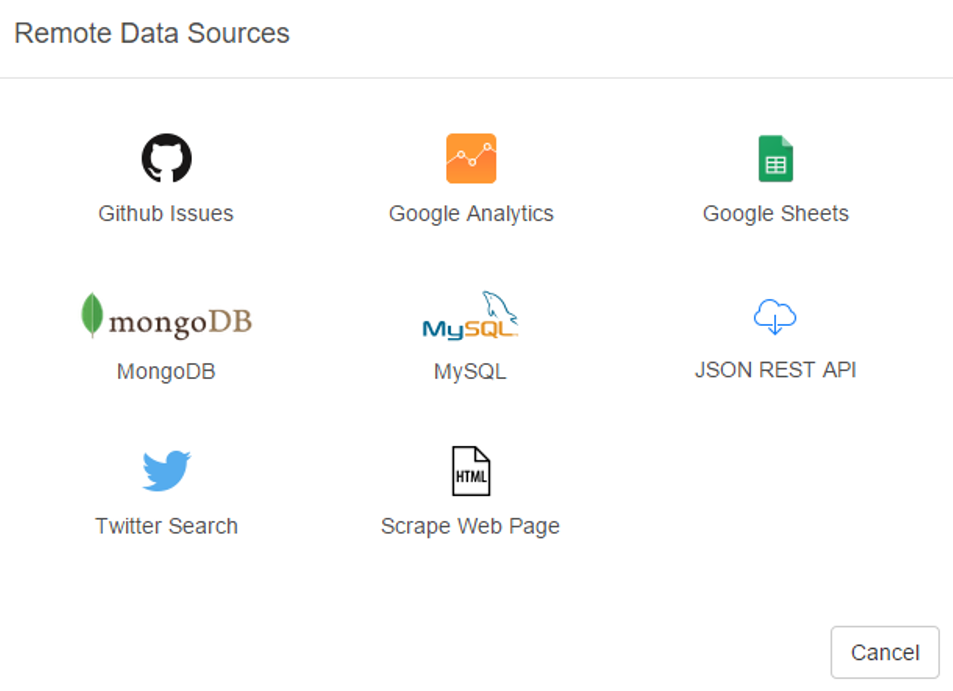
Great! Not only can we gain direct access to MySQL databases (a huge plus for me), Exploratory also provides access to a diverse range of option including Twitter search, MongoDB, and web scraping. We’re going to look at some specific examples later, but for now, here’s a glimpse of the MySQL data import window:

As with the entire app, the design is clean and intuitive. In a bit, I’m going to load details into this window so we can test the MySQL functionality.
A third import option exists in the availability to access any existing R scripts you may have previously created:

I’m not going to spend a lot of time here, due to the fact that I don’t have a lot (any?) of personal scripts. However, for seasoned R coders, this seems like a great feature.
Now let’s walk through some of Exploratory’s capabilities using a MySQL connection. The MySQL setup is really easy – just fill in your database connection parameters and you’re good to go. Here’s what it looks like for this example, with a few fields grayed out for security reasons.
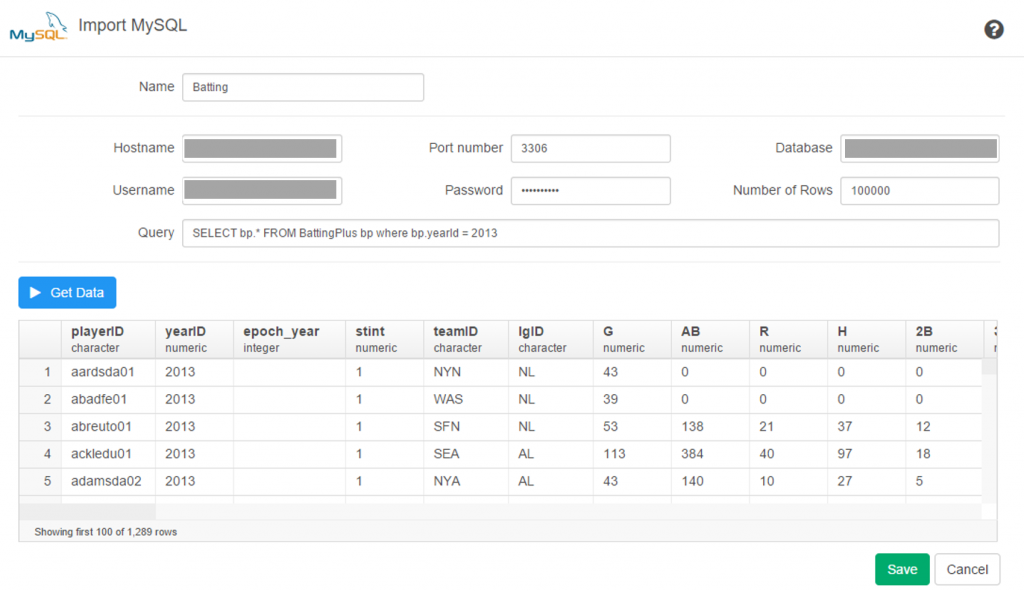
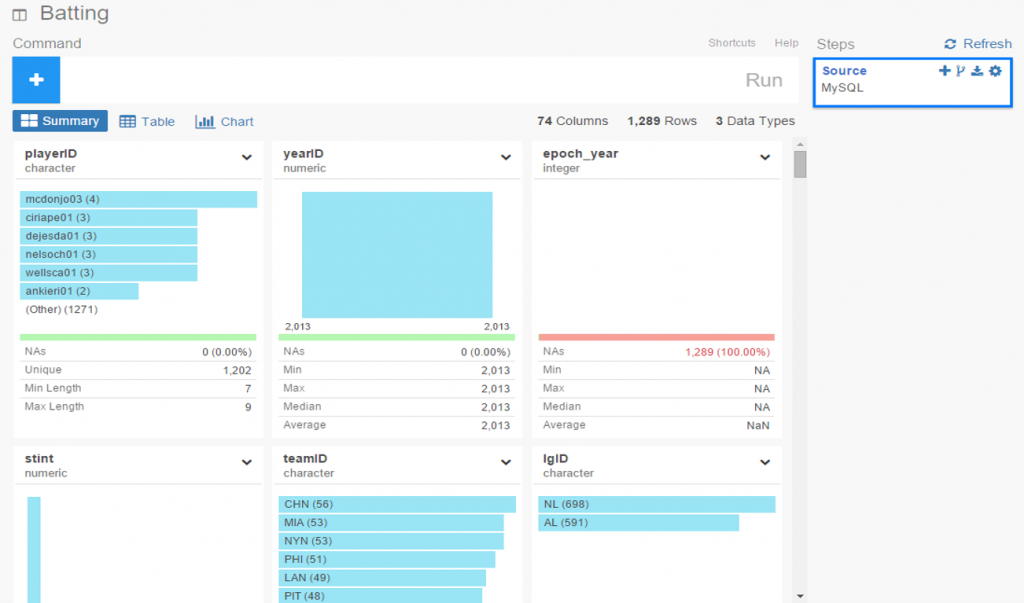
Once the connection is established, Exploratory will display the initial rows in the dataset. If we click the Run button, our data is pulled into a Summary view, where every variable in the data is summarized. This is a great way to see if our data looks as expected, and allows us to determine if the correct variable type (integer, date, etc.) is associated with each field.
If everything looks good, we can move on to the Table option, which will resemble the MySQL view we just saw. No surprises here:
If we’re satisfied so far, then it’s time to move on to the fun aspects of Exploratory. For me, this starts with viewing data using the Charts selection. As of this writing, there are 10 chart options (two are actually mapping selections for geo data) including bars, scatter plots, box plots, heatmaps, and more. For me, this is a real strength of Exploratory; the ease with which we can see plots of our data is great! Here I’ve chosen a couple stat fields (at bats (AB) and runs (R)) to illustrate the scatter plot functionality.
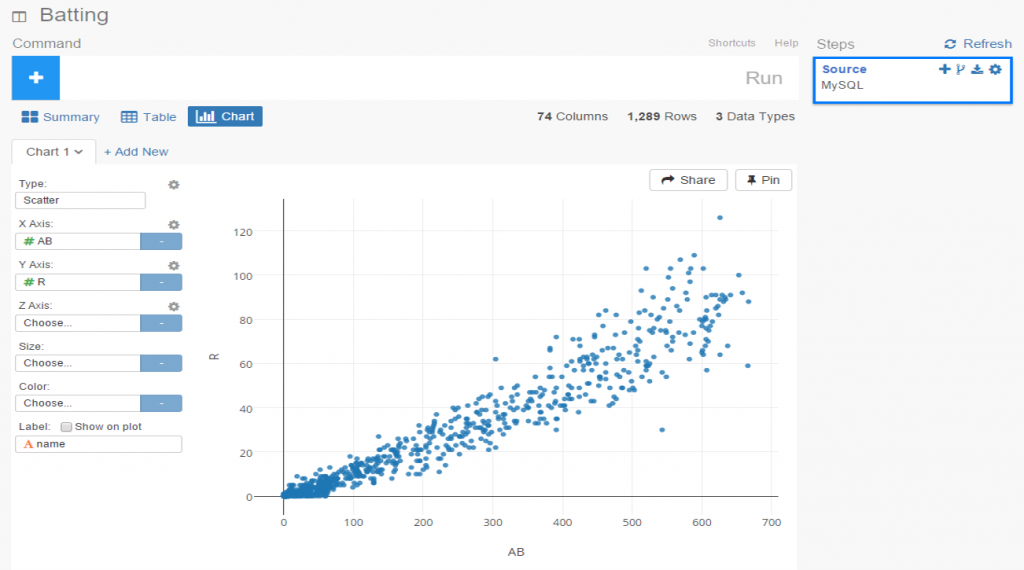
The charts are clean and attractive, and provide some additional options. For scatter plots, labels can be added via a simple check box. This permits me to add hover labels, as seen below:
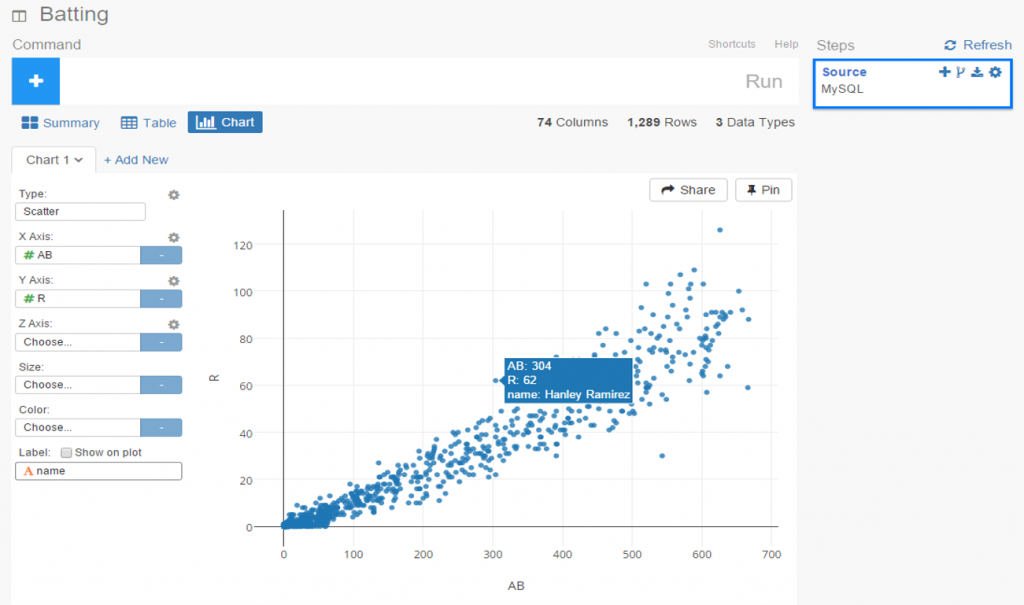
Pretty nice so far, don’t you think? But as the old commercials used to say ‘wait, there’s more’. The considerable power of R lies beneath the surface, enabling statistical testing, filtering, data manipulation, and so much more. Here’s a glimpse of just a handful of available options for working with your data:
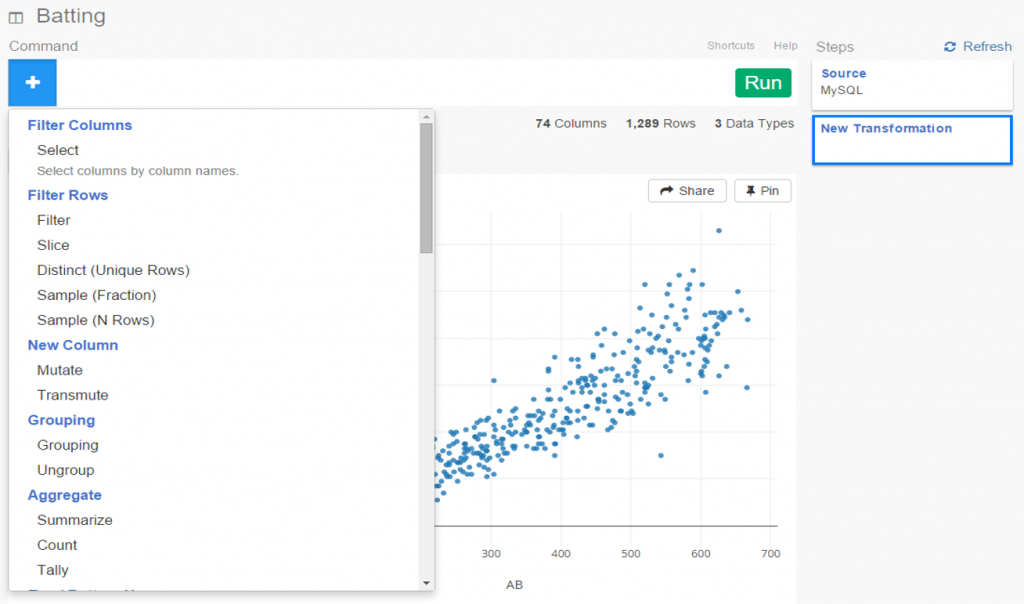
Let’s select a filter option, where we’ll reduce the data to look only at players age 30 or greater. One of the other great aspects of Exploratory is it’s exposition of R code. We can use the built in menu commands while viewing the actual R code. For experienced R users, the functions can be entered directly in a text box, and for us less experienced coders, we can learn on the fly by seeing the output.
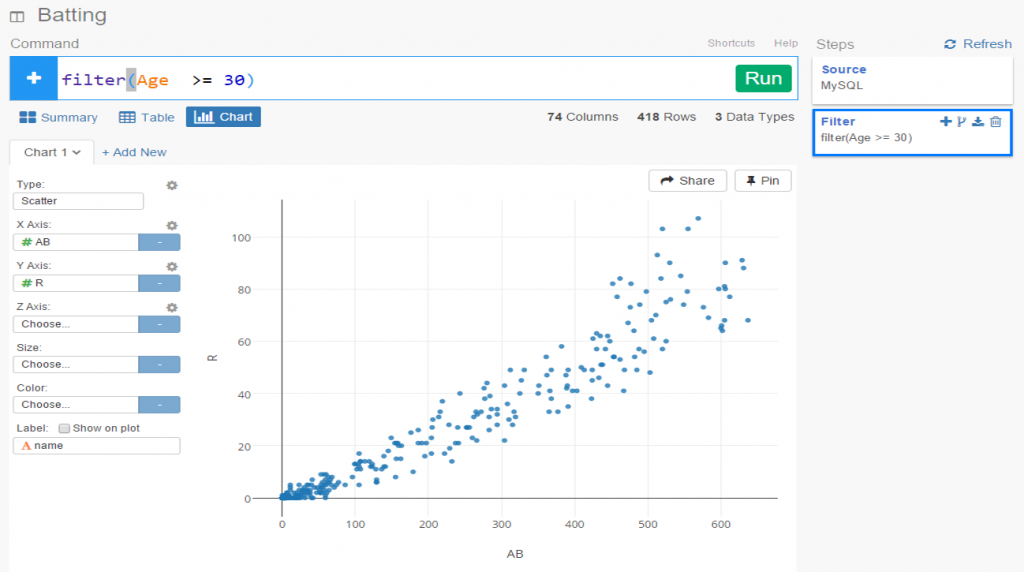
Now we see the same scatter plot populated with players 30 and older.
Another great feature is the ability to create branches within a project. This facilitates going down multiple paths within one workspace, rather than having to retrace our steps or rerun charts each time something changes. All we need to do is click the branch button, and a new tab is created for us. Very simple and intuitive, as is virtually everything in Exploratory.
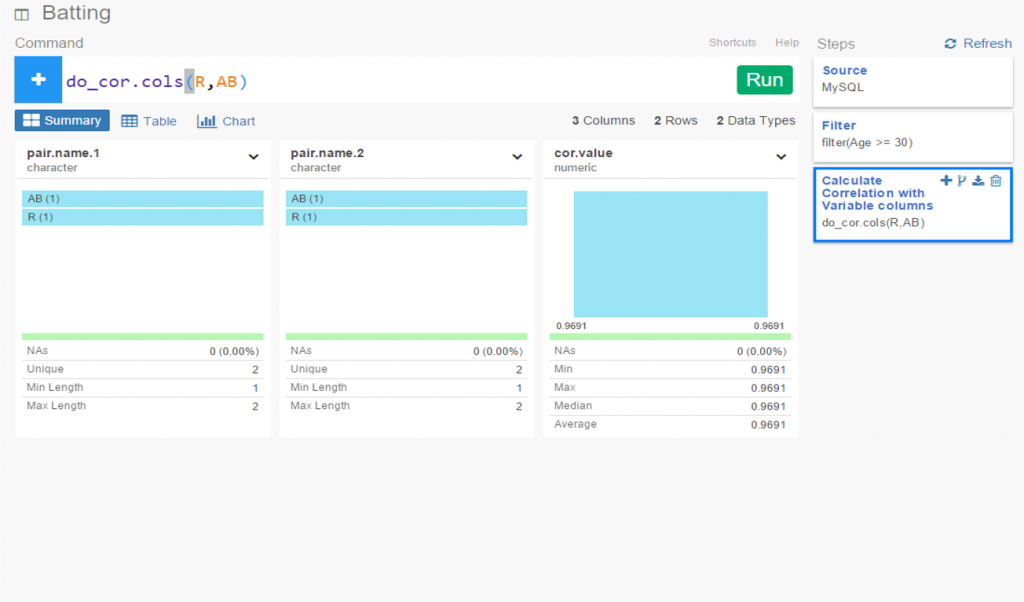
In this instance, we’ve elected to run a correlation on the chart variables in our main flow, while we create a new box plot in our branch.
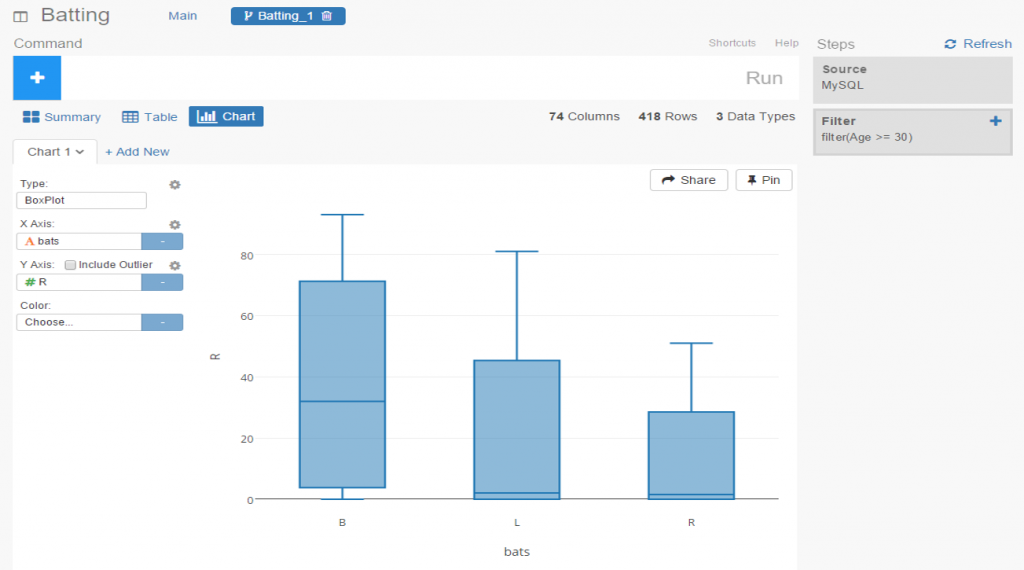
I’ve been very impressed thus far with Exploratory, and have barely scratched the surface. My next step will be to create some real content that can be shared in a post or via some new visualizations on the site. I love the ease of accessing my data via MySQL, and immediately having the ability to create plots, filter data, and run statistical explorations.
