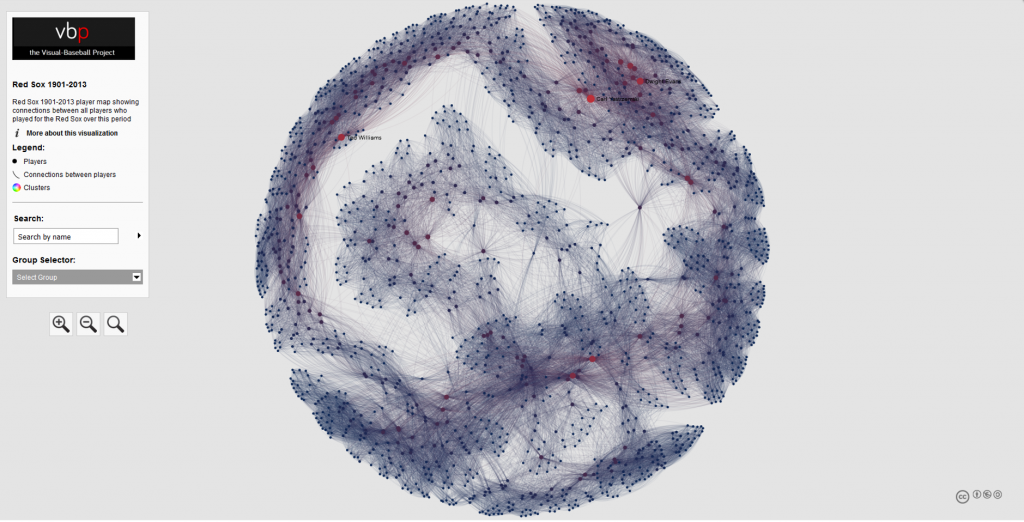
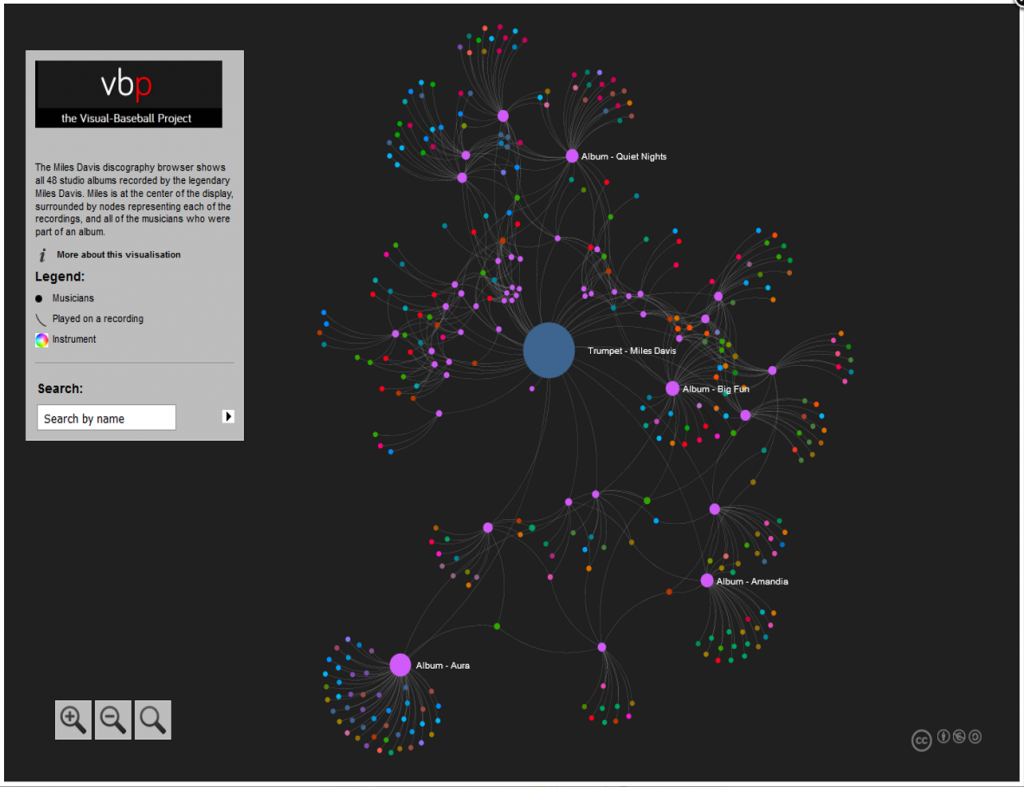
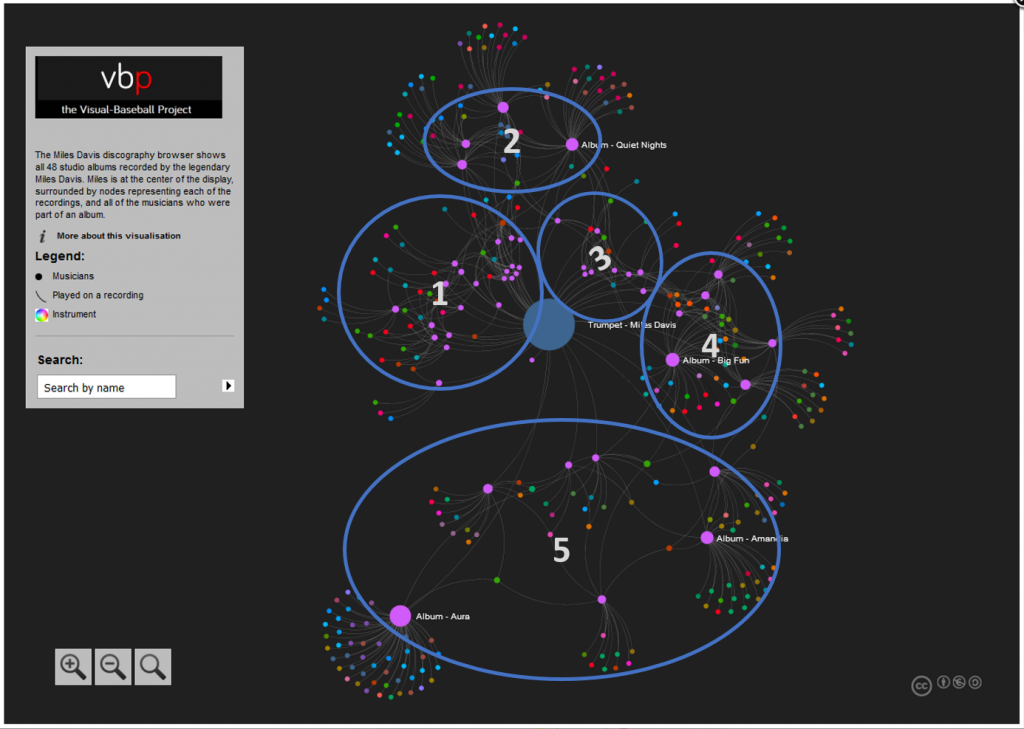
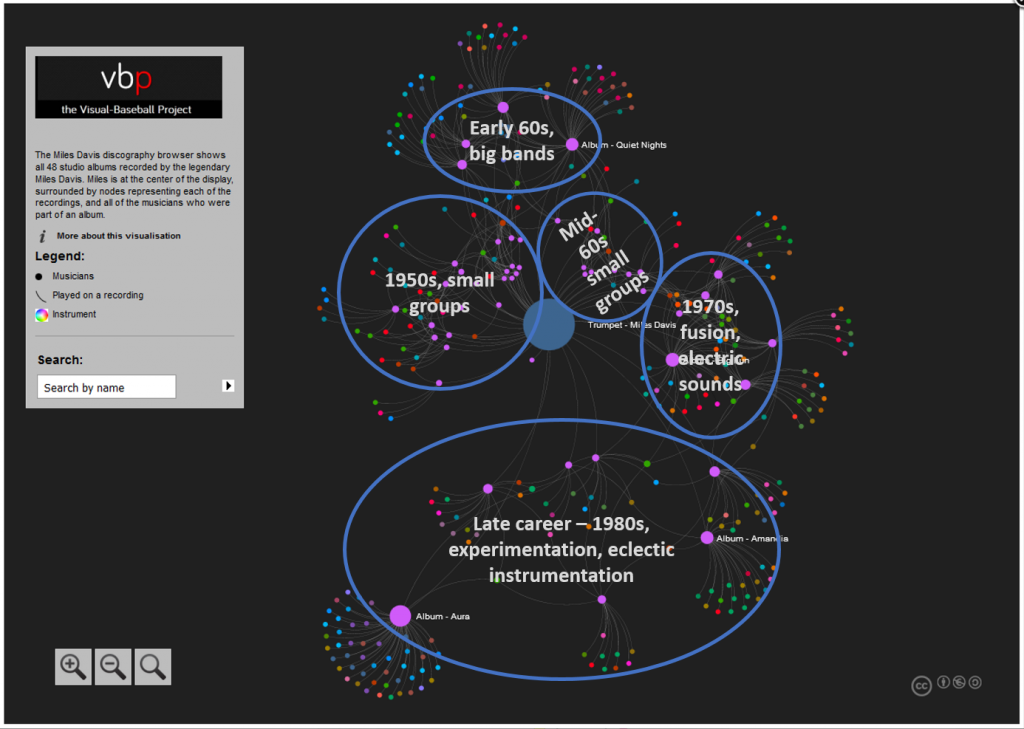
In our previous post, we looked at how to acquire and load our baseball player data into Gephi. In this second installment, the focus will be on creating a player network graph in Gephi, and customizing many settings to deliver a network graph we can export to the web. Player networks are used to detail the connections between all players who are connected to one another in some fashion. In this instance, it is based on players having played for the same team in one or more common seasons. So let’s begin with the process of creating the graph using our raw data from the first installment.
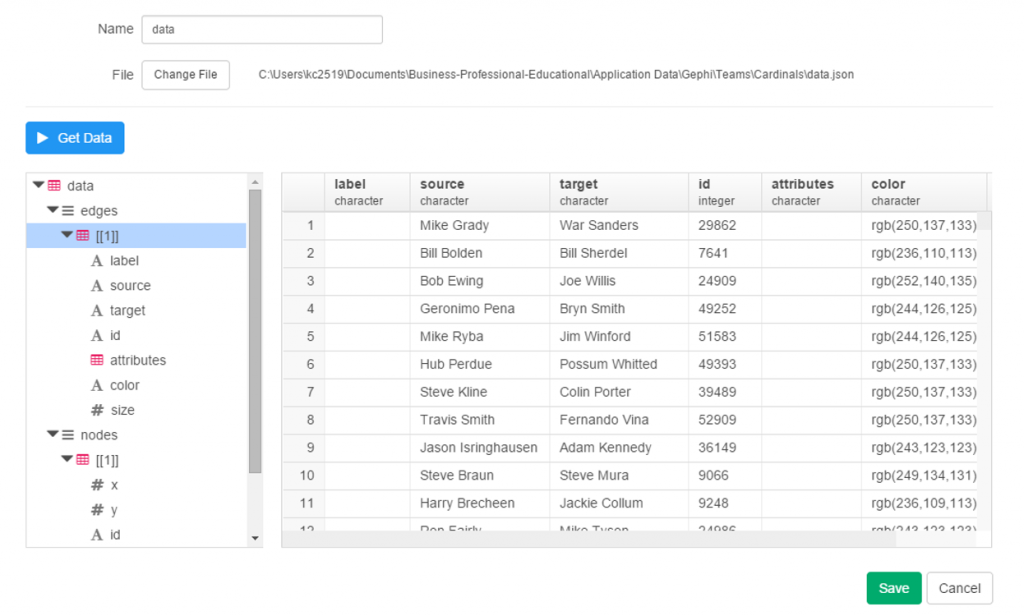
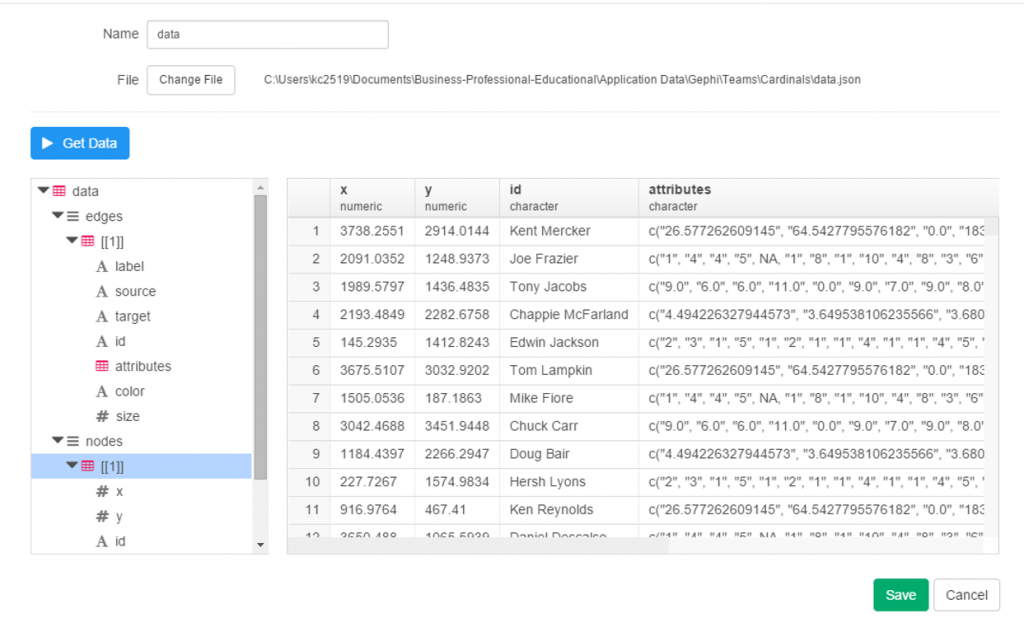
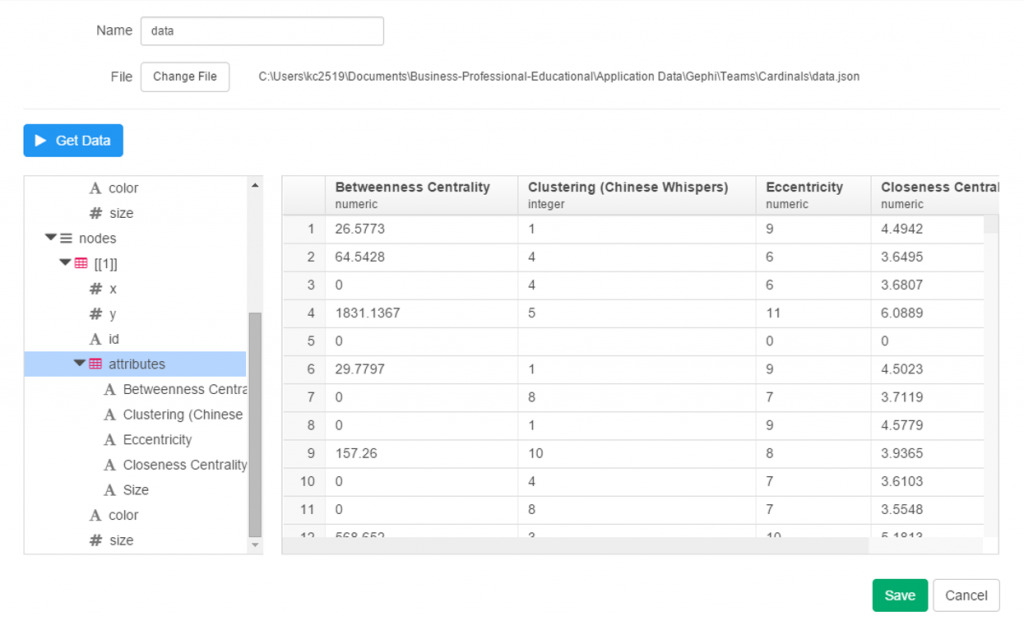
Importing .csv data into Gephi is quite simple – we create individual node and edge files (as we showed in the previous post), and use the Gephi import functions to pull the data in. I always start with the node file, since it will typically have additional information not included in the edges file. After importing the node data, I then import the edge data, which gives us the information to form our initial graph. If we were to start with the edge file, Gephi will create our node data automatically, and we will not have the detail needed for our graph. This approach may work for simple graphs, but not for our current case.
Once both data files have been imported, we can begin thinking about what we want form our graph. Here are several questions we might pose:
- How will we use color?
- What sort of layout will be best?
- Which measures should we calculate?
- How should we depict node sizes?
In many cases, the answers to these questions come about through trial and error. We may have some ideas going into the process, but invariably, there will be modifications along the way. So be patient, and be willing to experiment as you create network graphs. The graph you will see in this post went through many of these modifications, which I won’t take the time to detail. Instead, this post will detail my final choices, along with some explanations for why these choices were made. So let’s take a walk through the various facets of the visualization.
Layout
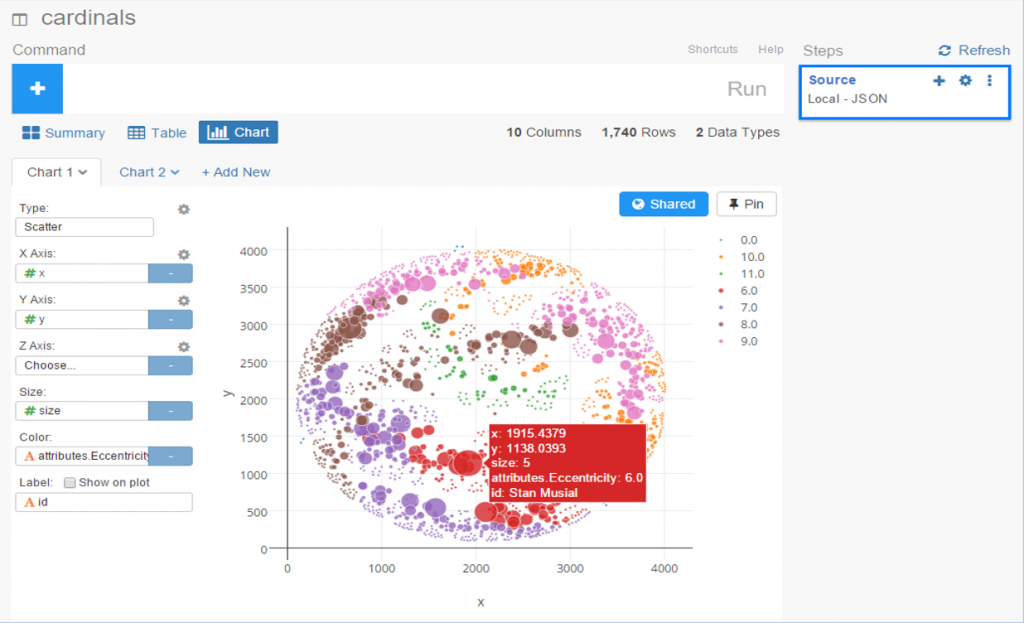
While a network will retain the same underlying structure from a statistical point of view (degrees, centrality, eccentricity, etc.) regardless of our layout choices, it is still important to select a layout that will visually represent the underlying patterns in the network. Otherwise, we could just as well deliver a spreadsheet with all of the network statistics. So layout selection is critical, and often involves an iterative process.
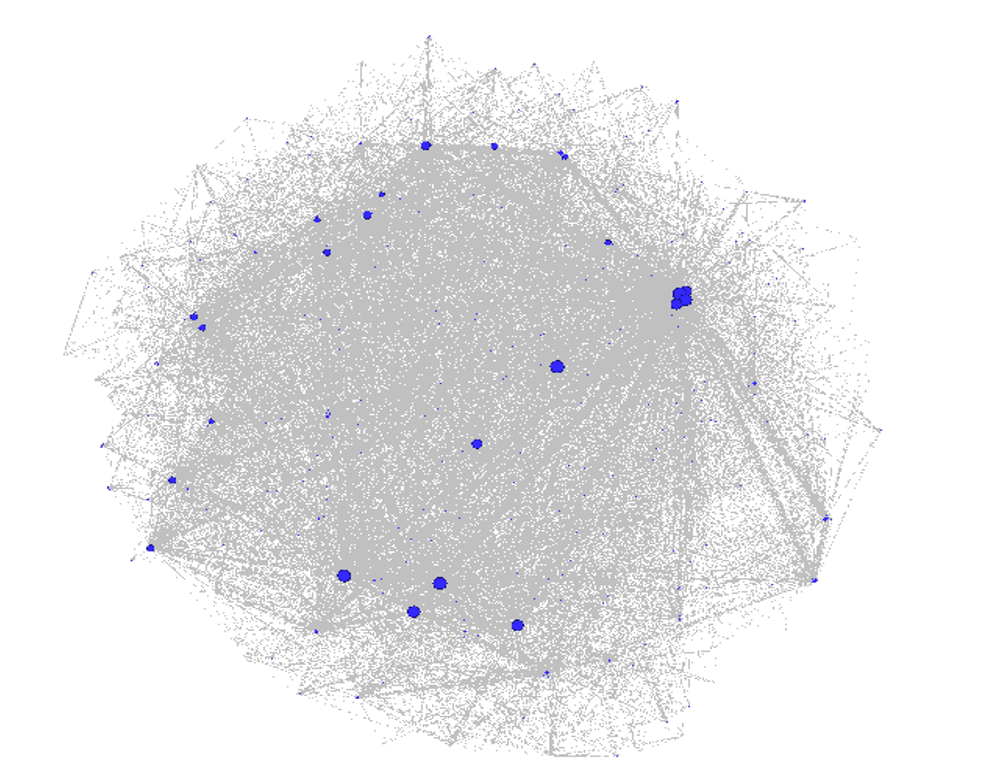
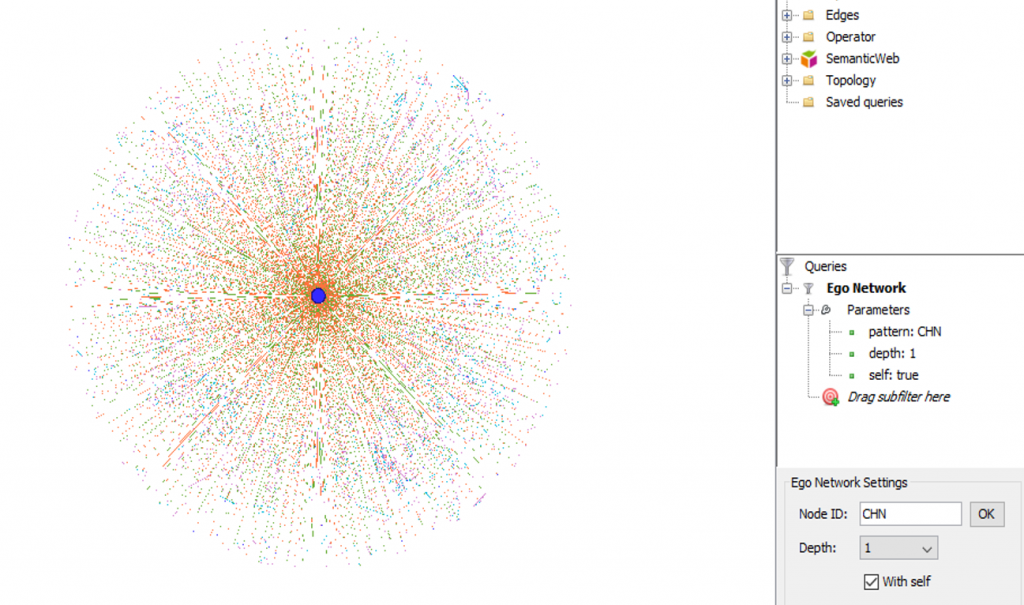
For the baseball network graphs I built in 2014, I eventually settled on the ARF layout algorithm, which ran quickly and created an attractive circular network graph display using the player connection data. Alas, there is no ARF algorithm available for Gephi 0.9.2, so I required a different approach for the updates. Ultimately, this led to a 2-step approach using a pair of layout algorithms – OpenOrd followed by Force Atlas 2. OpenOrd is especially effective at creating a quick layout from large datasets, although with far less precision than some other force-directed approaches. Still, it is a great tool for creating a general understanding of the structure of a network very quickly. Force Atlas 2, is the near opposite of OpenOrd – a very precise approach that can be tweaked easily using the various settings in Gephi. It is ideal for putting the finishing touches on what OpenOrd started.
Here are the settings I eventually settled on for Force Atlas 2, after much trial and error:
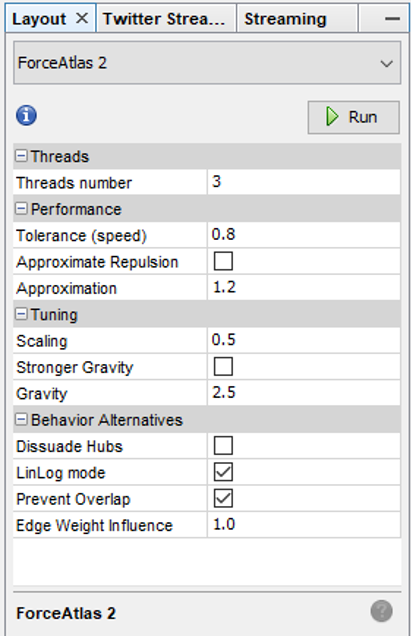
Some of the more important things to note here are the Scaling and Gravity settings. I reduced the scaling to 0.5 so the network would display appropriately in a single window without the need for scrolling. The Gravity setting was increased to 2.5 to force nodes slightly toward the center of the display. The LinLog mode and Prevent Overlap options are also selected in order to make this particular graph more visually effective. For other graphs, I have used the Dissuade Hubs option, forcing large nodes to the perimeter of the graph; in this case, that was not an ideal choice.
Color
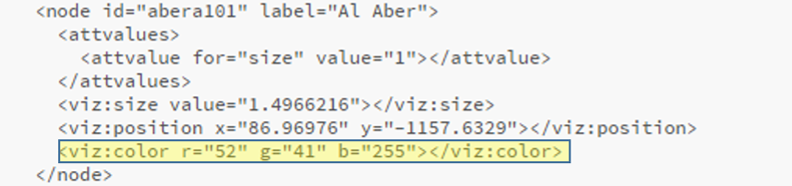
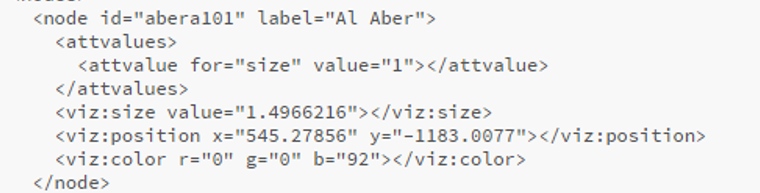
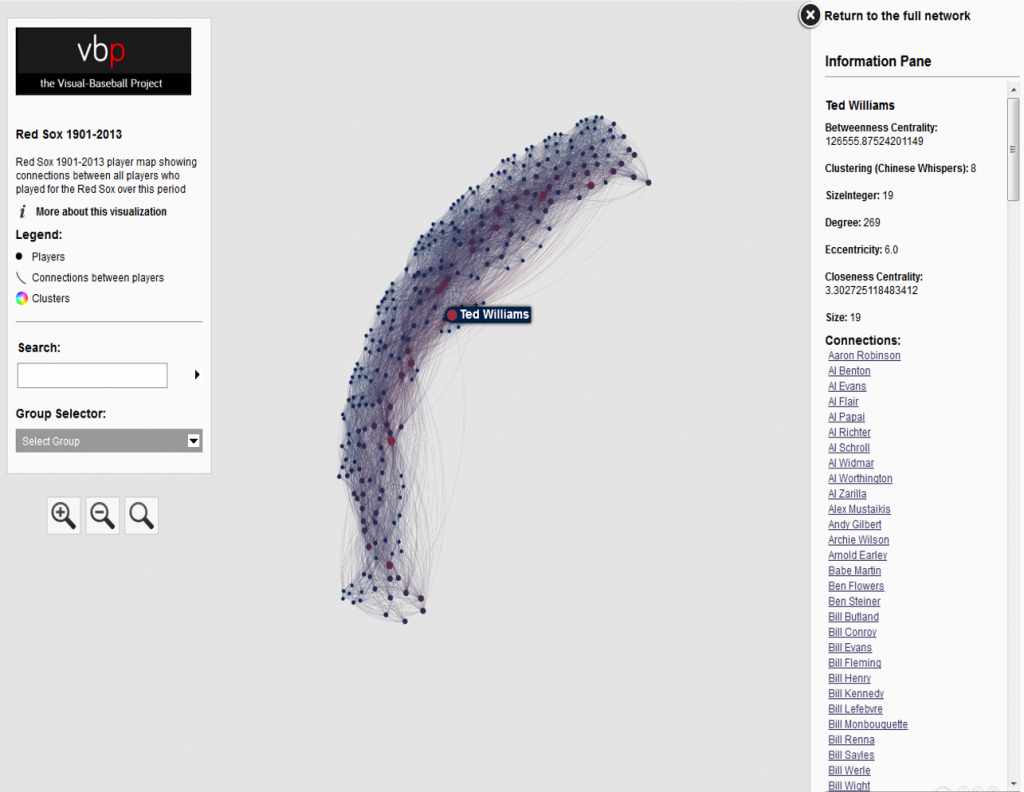
The use of color is also important within a network graph display. Color can be used to highlight nuances in the data that distinguish one or more nodes relative to another group of nodes. Often we use color to visually represent clusters within the graph, as grouped using the modularity classes statistic or some similar input. In the case of this series of graphs (ultimately one graph per team), I made a decision to use the official team colors to differentiate each graph. Thus my initial graph for the Boston Red Sox would be based on the two primary hex colors for the current team (these colors do change over time for many teams).
Here are the Red Sox primary colors:


After capturing current team colors in a spreadsheet for easy reference, I used the color-hex.com site to select complementary colors for the Red Sox graph. Using complementary colors allows me to differentiate clusters in the graph while remaining true to the original concept of employing team colors for each graph. So instead of a wide range of colors one would normally see in a Gephi output, I was able to input the complementary colors for each group. Thus, one team color could be used for the graph background, while the other color (and it’s complements) could be used for the graph structure (nodes & edges). We’ll share the effect later in this post.
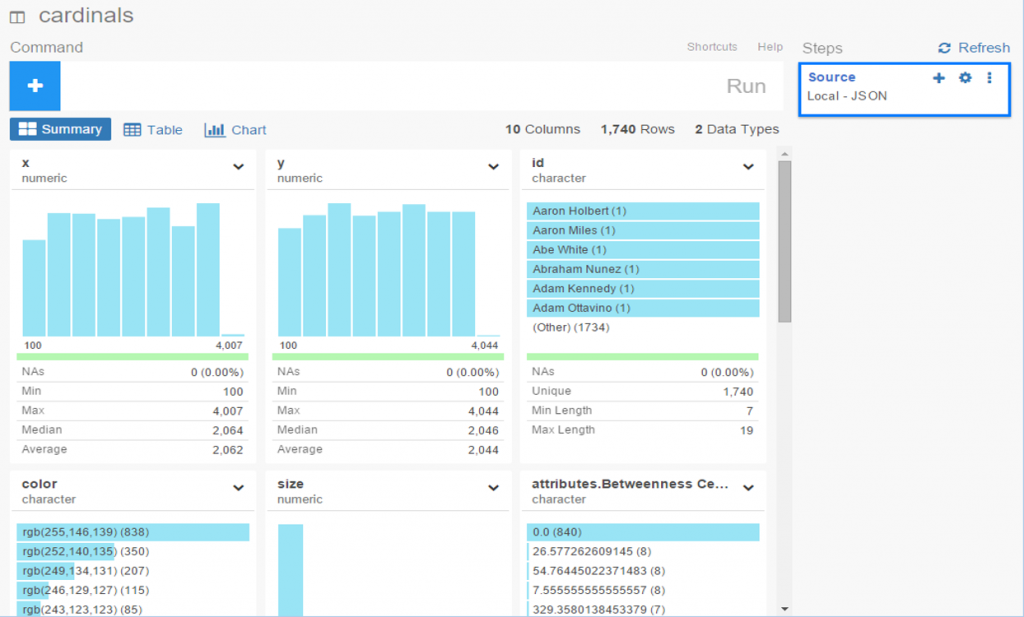
Statistics
Graph statistics are critical to the full understanding of the structure of a network. While we can view a graph and begin to understanding the general structure of a network, the various statistics will aid and reinforce our initial visual comprehension. Gephi provides a nice range of statistical measures to choose from:
- Eccentricity (the number of steps needed to traverse the network)
- Centrality – betweenness, eigenvector, closeness, harmonic closeness (various measures of importance of an individual node)
- Clustering coefficient (to discern cliques in the network)
- Number of triangles (a friends of friends measure)
- Modularity Class (clusters)
- Degrees (the number of connections)
Sizing
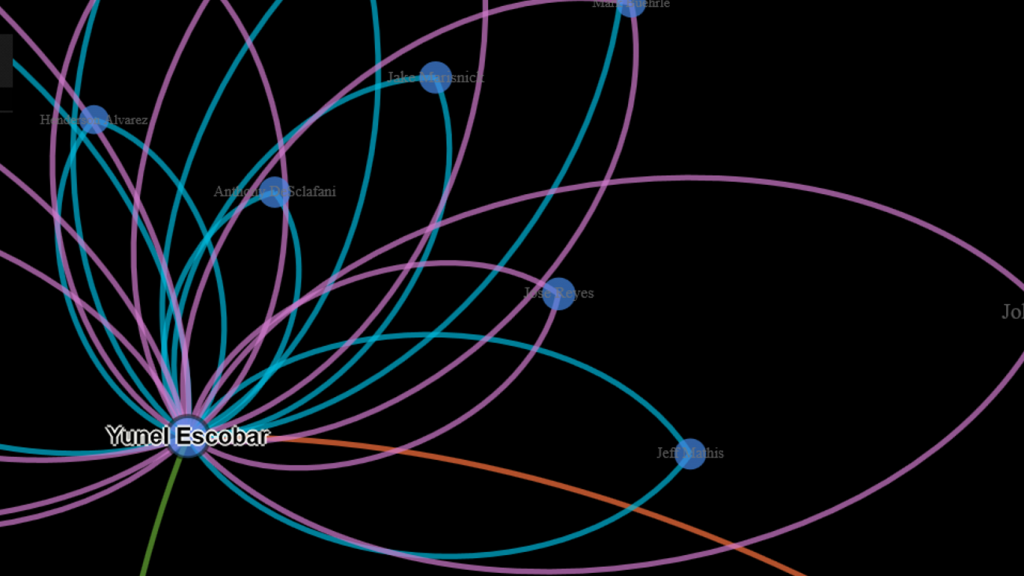
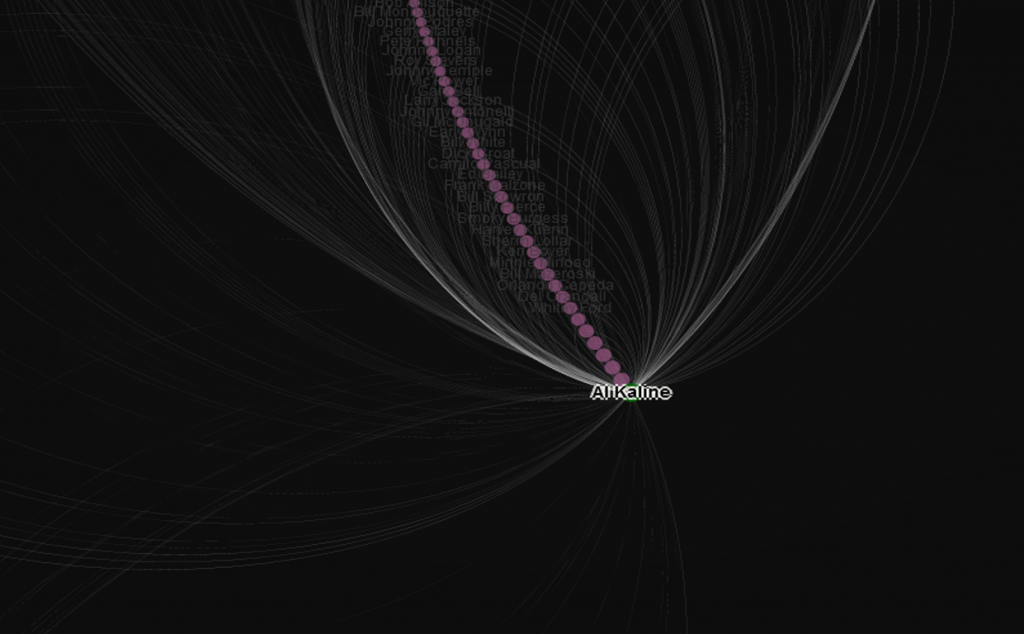
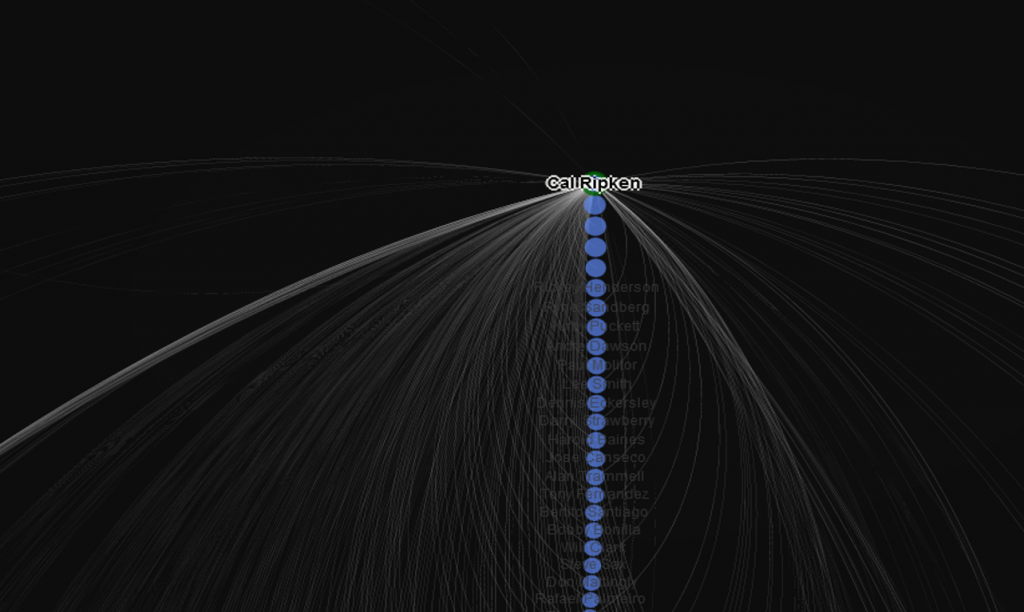
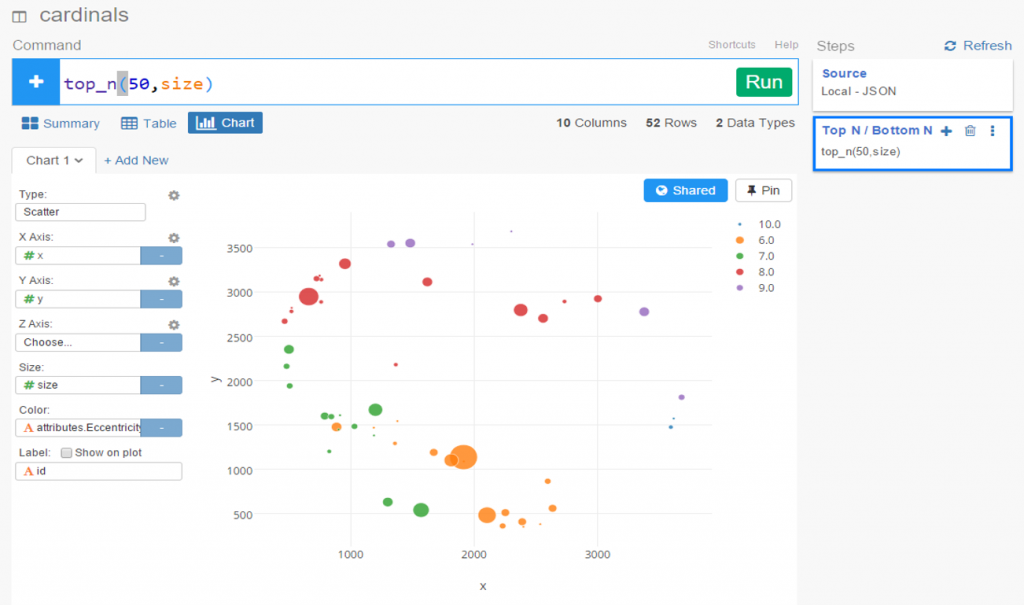
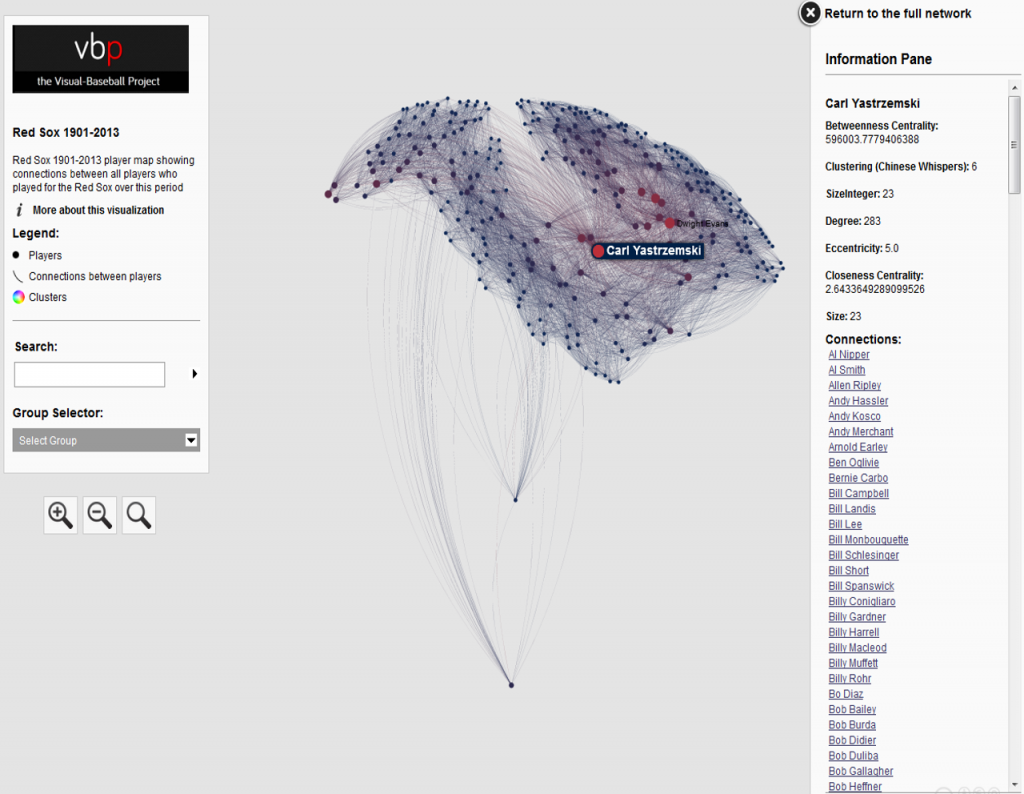
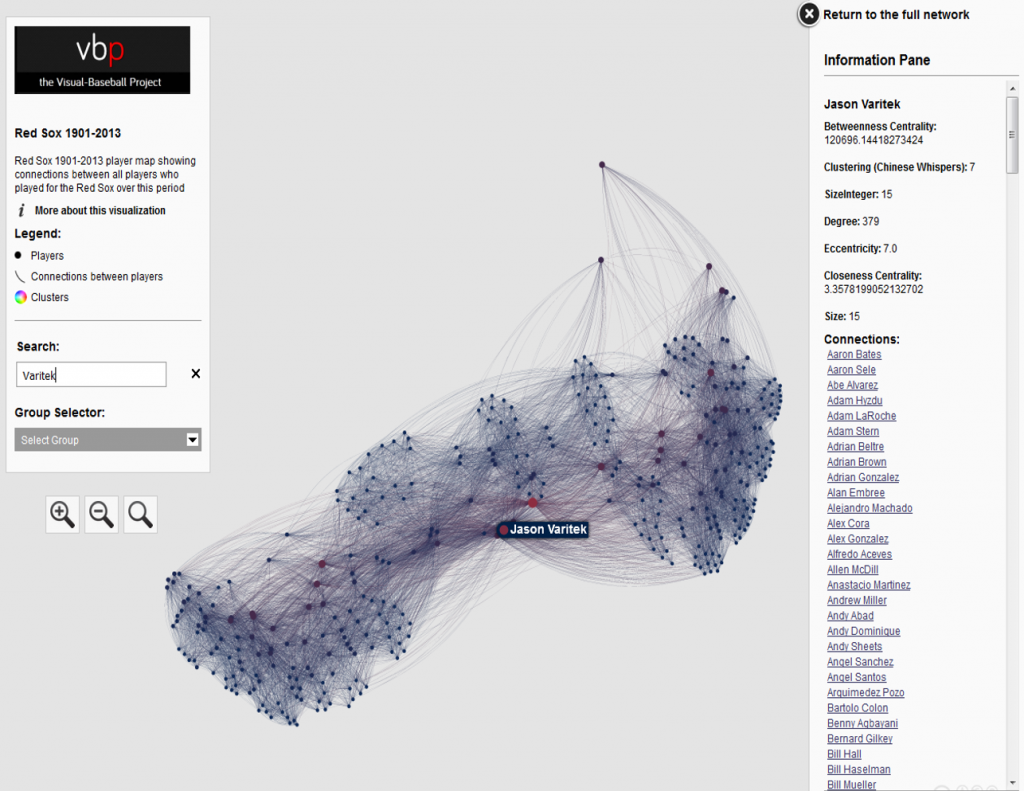
Node sizing is another key element of effective graph design. In this case, there were a few options I could pursue for node sizing – the number of seasons played (I used this in the 2014 graphs), one of the various centrality measures we calculated, or the number of degrees (connections) an individual player possesses. After computing each of these statistics, I eventually decided to use the number of degrees as a representation of influence in the graph. Visually, I want to show how many other players a single individual is related to, and using node size is an effective means of doing so.
Summary
Our final graph in Gephi is shown below; the eventual web-based version will differ slightly and include additional functionality, but that’s for another post.

Next Post
My third and final post in this series will address exporting this graph to the web using the sigma.js plugin, and making some additional customization to the web version. Thanks for reading, and see you soon!